
PDF Table Extractor
This tool lets you extract data tables from PDFs into an editable tabular format directly in your web browser, ready for export to CSV or Excel.
I came up with the idea for this app while designing a data collection project that involved scraping data from thousands of corporate disclosures in PDF format. The disclosures came from different companies; each table had the same information but formats varied widely and the specific table we were after might be anywhere in a larger document, with a number of other tables mixed throughout. This meant the out-of-the-box Tabula software wouldn’t work well - while it does a great job getting the data out, using it in a batch process would create just as much of a mess sorting the extracted data into our standardized format.
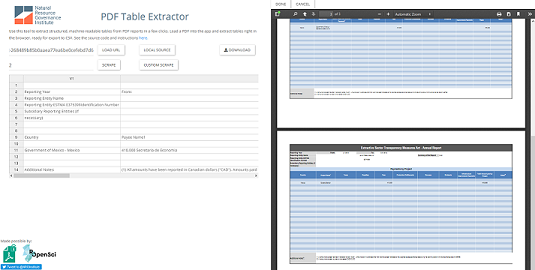
I needed something I could hand off to our researchers to maximize both their accuracy and efficiency. To me, that meant a side-by-side interface: target PDF on one side, to locate the correct table and see the original data, and an editable table on the other, for the extracted data. Using R-Shiny, I could create this interface, and Tabula, via the Tabulizer R package, made the critical connection between the PDF and the editable table. Now, our researchers could locate the table, use Tabula to extract the data, and reformat and clean the extracted data all in one place.
With this application tailor built and deployed for our internal project, I decided that such a tool would be useful to the wider open data community, and created the PDF Table Extractor.
The application is built in R-Shiny and utilizes the brilliant open source Tabula program via the R package tabulizer.
See the app here: apps.resourcegovernance.org/pdf-table-extractor